Project Overview
Financial research is bottlenecked by document volume. Analysts manually reading through hundreds of 10-K filings, income statements, balance sheets, and cash flow reports to answer questions that should take seconds — not hours. FinSight solves this.
FinSight is a production-grade RAG application that indexes 50M+ tokens across 402 S&P MidCap 400 companies' financial statements and filings. Ask any financial question in plain English and receive a sourced, cited answer in seconds — with full conversation memory so follow-up questions work naturally.
Key achievement: Reduces financial research time from hours to seconds with full source attribution. The multi-layer caching system reduces OpenAI API costs by 40–70% in production use — making the system economically viable at scale.
RAG Pipeline Architecture
Every query flows through seven stages — from cache lookup to final GPT-4o generation. Each stage maximizes answer quality while minimizing API cost and latency:
1. Cache Lookup
Check query result cache first — matching queries return instantly (<50ms). Smart invalidation skips cache for follow-up questions needing fresh context.
2. Query Expansion
GPT-4o generates 3–4 alternative phrasings to capture different financial terminology. Improves recall by 30–40% for domain-specific questions.
3. Zilliz Vector Search
3072-dimensional embeddings search the Zilliz cloud vector database. Retrieves top 30 documents with hybrid semantic + metadata filtering by ticker and doc type.
4. MMR Reranking
Maximal Marginal Relevance reranks 30 docs to 10, balancing relevance with diversity — preventing redundant information in the context window.
5. Contextual Compression
LLM extracts only the relevant sentences from each chunk — reducing context by 40–60% while preserving critical financial figures.
6. Conversation History
Last 3 exchanges (max 4000 tokens) prepended for follow-up question support and pronoun resolution across turns.
7. GPT-4o Generation + Cache
GPT-4o generates the final answer with [Source N] citations, ratio calculations, and trend analysis. Response cached for future identical queries.
Core Features
Conversational AI
Multi-turn conversations with context memory. Follow-ups like "What about 2025?" work naturally after any previous question.
Source Citations
Every answer includes [Source N] references with filename, document type, and similarity score. Full auditability — no black box.
Smart Caching
Two-layer caching reduces API costs 40–70%. Repeated queries return in <50ms vs 2–4 seconds for novel queries.
Financial Ratios
Auto-calculates 19 financial ratios with formulas, extracted figures, and step-by-step workings on demand.
Hybrid Search
Combines semantic similarity with metadata filtering by ticker, document type (income statement, balance sheet), and date.
PDF Export
Download any analysis as a formatted PDF report. Query history tracking lets users reference and reuse previous searches.
Pipeline Deep Dive
Query Expansion
The system generates alternative phrasings to capture different ways financial questions can be expressed:
Input: "What was revenue in 2024?" Expanded to: → "What was total revenue in fiscal year 2024?" → "Show me contract revenue for FY 2024" → "What were the sales figures for 2024?" → "Revenue reported in annual report 2024" Improvement: 30-40% better recall on domain queries
MMR Reranking
After retrieving 30 candidate documents, Maximal Marginal Relevance selects the best 10 by balancing relevance with diversity — preventing the context window from being filled with near-identical chunks. A 3× retrieval-to-selection ratio ensures the best content surfaces even when the top results cluster around the same source.
Contextual Compression
Rather than passing full document chunks to GPT-4o, a lightweight LLM pass extracts only directly relevant sentences — reducing context by 40–60%. More documents fit in the window, and generation quality improves because the model processes signal rather than noise.
Engineering trade-off: Each pipeline stage adds latency but improves answer quality. The caching system compensates — frequent queries bypass most of the pipeline entirely, keeping average response times competitive while maintaining full quality for novel queries.
Conversation Memory
Unlike single-turn Q&A systems, FinSight maintains conversation context for natural financial analysis workflows:
- Session architecture: Unique ID per browser tab, persists through page refresh via sessionStorage
- Context window: Last 3 exchanges (6 messages), max 4000 tokens with automatic pruning
- Smart cache bypass: Follow-up indicators ("what about", "compare", "that") automatically skip query cache for fresh context-aware responses
Multi-Layer Caching
Two independent cache layers eliminate redundant API calls — the primary cost driver in production RAG systems:
Embedding Cache
Query Result Cache
Production impact: Combined caching reduces total OpenAI API costs by 40–70% in sustained use. For a system running expensive GPT-4o and text-embedding-3-large calls at scale, this is the difference between a viable and non-viable production cost structure.
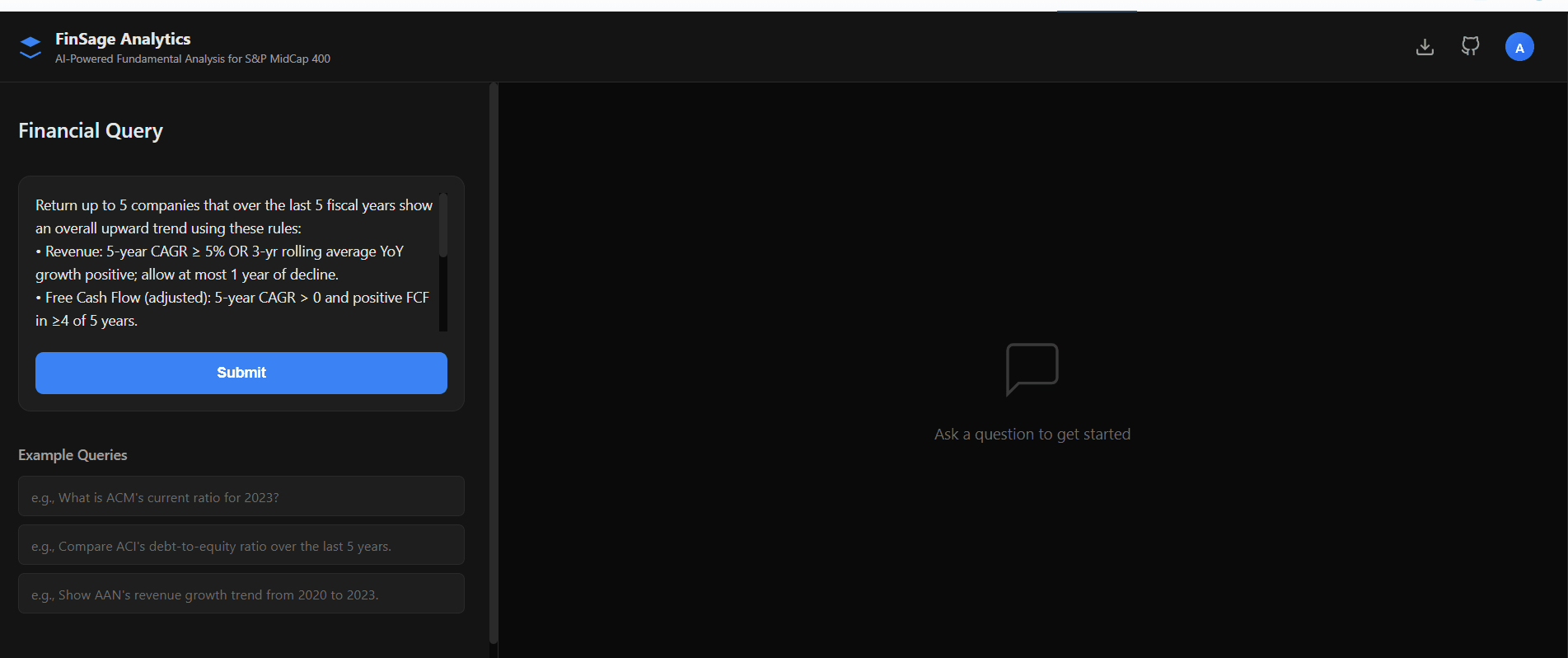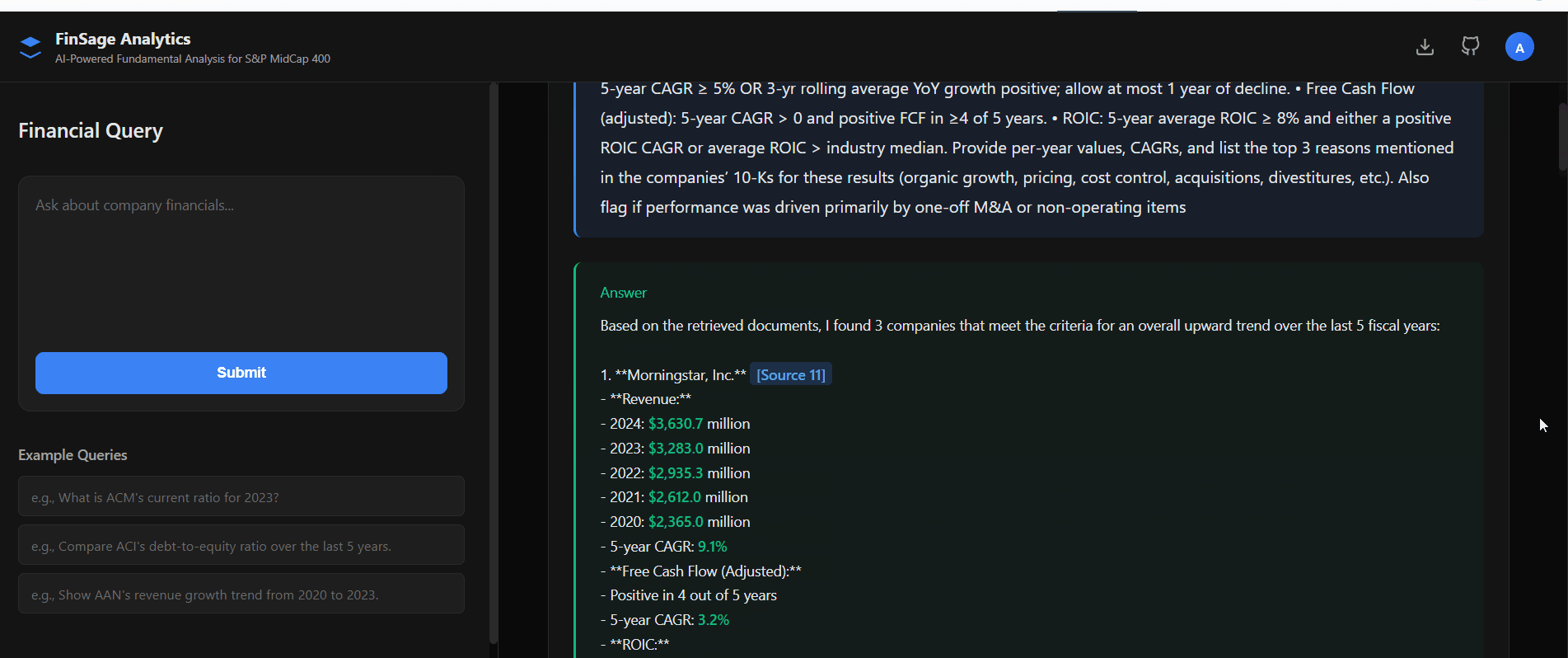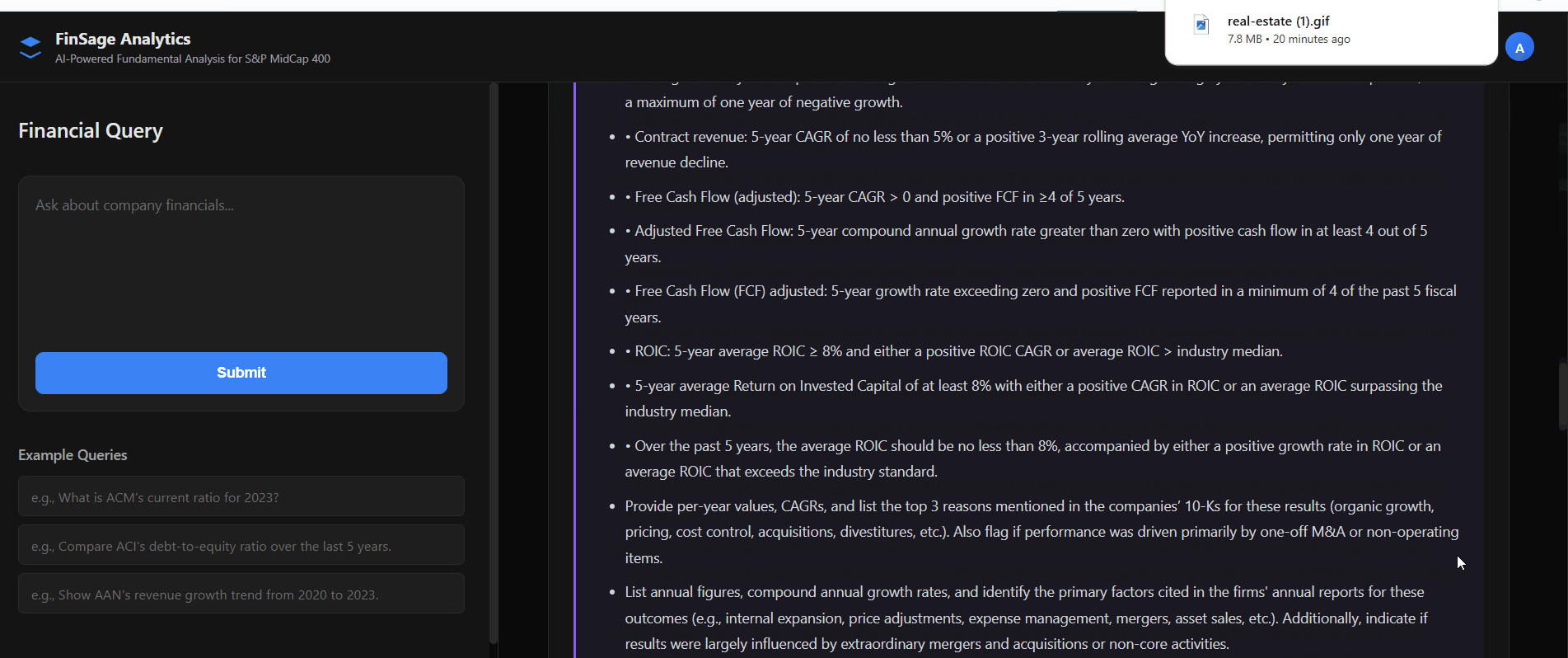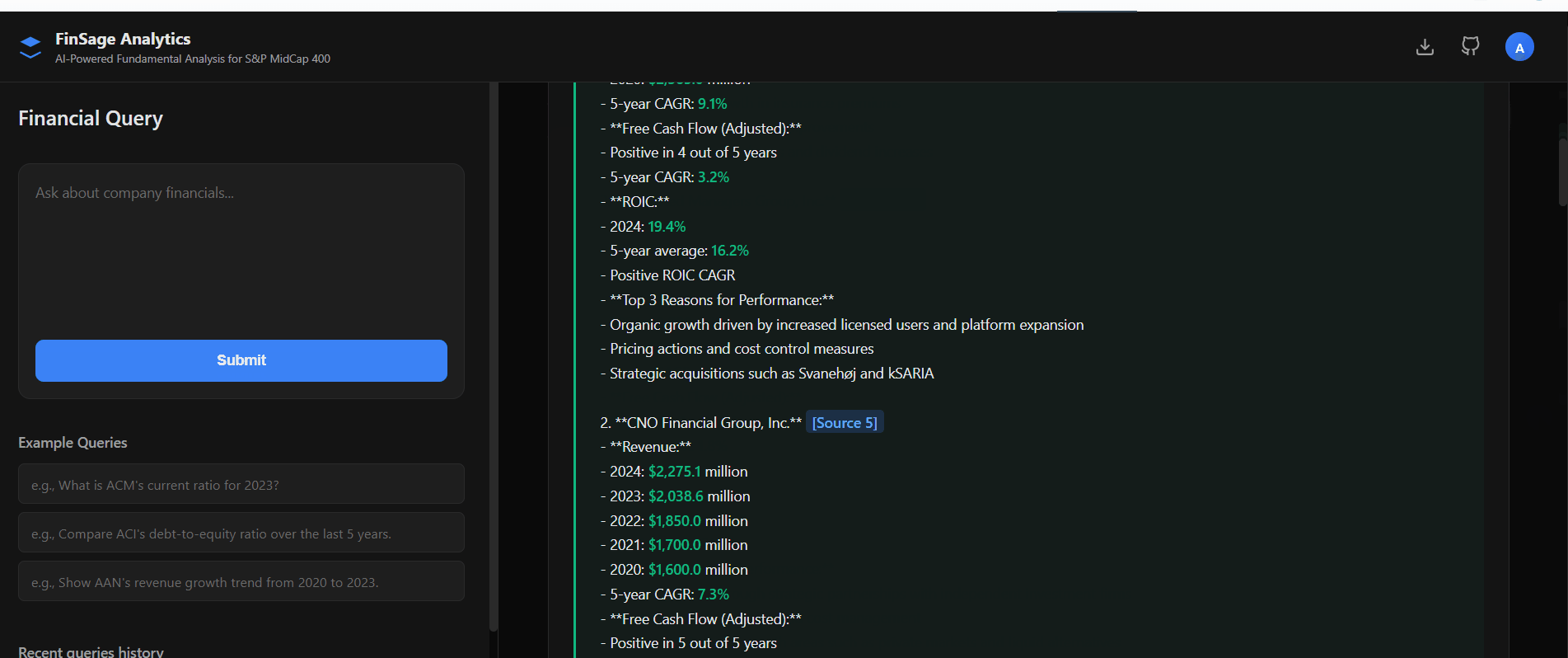
19 Financial Ratios — Auto-Calculated
The system prompt encodes formulas for 19 ratios. Ask any ratio question and receive the formula, extracted figures, calculation, and cited result:
Q: "Calculate ACM's current ratio for FY 2025" A: ACM's current ratio in FY 2025 was 1.13 [Source 1]. Formula: Current Assets ÷ Current Liabilities FY 2025: $6.73B ÷ $5.93B = 1.13 [Source 1] ACM_balance_sheet.md Balance Sheet | Similarity: 94.2%
Live Demo
FinSight is deployed on Hugging Face Spaces. Ask any financial question about S&P MidCap 400 companies:
Tech Stack
API Reference
The FastAPI backend exposes a clean REST interface for integration into any Python application or data pipeline:
import requests
response = requests.post(
"https://your-finsight-instance/query",
json={
"query": "What was ACM's revenue in 2024?",
"ticker": "ACM",
"doc_types": ["income_statement"],
"top_k": 10,
"session_id": "my_session_123"
}
)
result = response.json()
# result["answer"] → Sourced answer text
# result["sources"] → List with doc metadata
# result["from_cache"] → True if cache hit
# result["processing_time"] → Seconds to generate
Additional endpoints: GET /health, GET /stats, GET /cache/stats, DELETE /cache/clear, DELETE /session/{id}. Full Swagger UI at /docs.